A tale from reverse proxies and traffic encryption

Defeating Issues
Reverse proxies, such a simple way to accomplish various things.
A cheap solution when it comes to handle DDoS Traffic, as only a few are able to finance a whole network to mitigate traffic. Unless you rely on OVH, which DDoS protection doesn't use a reverse proxy and is to good to be true, but actually really works and is free, you're going to use a reverse proxy which mitigates the traffic and transmit the clean traffic to your backend server(s).
But thats not all, we can also archive multiple other things, for example:
- Caching
- Loadbalancing
- Routing
Or we're using Cloudflare and it does similar things for us, it caches our content and also acts in the same way as a CDN and delivers content faster to the end-user. And of course Cloudflare is a reverse proxy, too.
The loss of Information
While reverse proxies provide a bunch of advantages, it contains one great disadvantage, as we loose one essential information about the client, his IP Address.
Ok, you'll say now: Well okay no problem, just tell the reverse proxy, in this example we will refer to NGINX, to attach a value like x-forwarded-for with the users IP Address within the http headers and we're done, arent we?
Well actually you're, if you don't need to use this information to load balance traffic behind your reverse proxy. Because now this gets a real problem!
Ok, then how to solve this problem?
Well, basically we do a really simple thing. When our balancers relied on the IP provided in the ip packet header as 4 unsigned chars (4x8bit) before, we know rely on an IP provided on layer 4, in this case included in the http headers. Take a look at Wikipedia to have an overview about the IP Headers.
What we need though, is a parser for the http headers instead. This is quite simple, we receive the packet, extract the information from this packet, balance over this information and resend the packet to this balanced target. This is quite easy to accomplish and has only a small overhead. We get an even smaller overhead if we skip the whole http stack and going to parse just the raw packet to extract our wanted information.
There are a couple of solutions, which are doing exactly this. For NGINX there is from version 1.7.2 upwards a build in way to do this:
This enables us to use any information we can access in NGINX, which is widely more than just informations from the http headers, this could be everything and any variable accessable in NGINX. Before version 1.7.2 we had only the ip_hash available which uses the ip from the ip packet. But there is actually a module for older versions:
To note, this NGINX solutions provide the whole http stack and thus are a little bit slower, as if you would only search for your information. But you've to decide yourself, how time critical your application is and how much time you want to loose before we actually process anything from the application itself behind these proxies.
Or if you don't want to manage the balancing via NGINX, but for example in your Node.JS application, which was in fact the inducement to write this entry as there appeared some interesting questions, you would use modules like sticky-session to hash balance all your connections via the IP between the different forks (workers).
Acutally sticky-session doesn't provide the ability to use the information from the http header instead, but there is an open PR from me, which is going to be merged somewhat soon. This pull request also contains the mentoined questions that were raised, take a look here if you're intrested:
https://github.com/indutny/sticky-session/pull/17
Other protocols
Ok, to now finally answer the questions that were raised in the PR. Let's start with the following:
BSSolo - Thanks, I can see now that you have also replaced the HTTP Server insance in the master process (as in the current version of this module) with a TCP server. That would certainly help with supporting other protocols such as web socket. Have you tested your header parser with protocols other than HTTP, or is it unnecessary since Web socket connections are initiated by HTTP upgrade requests?
Yes, it is possible with any protocol as long as you provide the information in the initial packet of the stream.
Therefore there are many ways we can do this, we go for this two as explanation:
The first one is, specify a general header like the HTTP Headers, in your protocol definition, which are always included in our initial packet. Thus we can parse the information from these headers.
We wrap the original initial packet and add this information at the very beginning. Now we just parse this information as usual and only resend the packet from the offset where this information is not contained anymore and the original packet gets restored. If we were in
C, we would just copy our pointer and increment the new one by 4 (4 bytes would represent an IPv4 Address). In Node.JS this would be similar, we would delete the first 4 entries. Probably we would just call thesliceofBuffermethod to create a copy starting from the defined offset.
Referring to this, the next question is the really interesting one.
SSL
Fedor Indutny - how will all of these work with, for example, SPDY?
In short, generally it would work, but not with the current code. The reasons for this are simple, but require some explanation.
Ok, let's start with SPDY. Or better let's start with HTTP/2, in which favour google has dropped SPDY.
There are a couple of differences, which do not allow us to do exactly the same, as I have done in this module. Which is pretty much exactly what I described before. There are some differences:
First of all, HTTP/2 is mostly used together with SSL. Some also describe HTTP/2 as SSL only. Of course it is not, this would be a problem in some edge cases I will describe further, later. For the reference, this information comes from this Mailing List:
http://lists.w3.org/Archives/Public/ietf-http-wg/2013OctDec/0625.html
Well, okay so we have SSL. That means we have one Issue already: We can't parse the incoming packet, we need to decrypt it first. But that is not all, unless we're going to create another reverse proxy or use a specialized component, we also need to decrypt this packet twice. When we're transferring the Socket from one fork to another, this fork doesn't know anything about what happened before. Or better, it shouldn't know about it and shouldn't have to care about it.
You maybe already noticed, that we probably do have some problems here!
The wasted CPU cycles for decrypting the same packet twice is one of this problems. But the real problem is another one, we need to reannounce the packet to the new fork to which this packet should get balanced. We also need to share the information of the TLS Session, to enable the fork to actually decrypt the packet and continue communicating with the client.
Another way would be to make the fork aware of the initial packet, which is not encrypted and then continue communicating encrypted, however, the fork still needs the TLS Session to do so. Ok, assuming we've accomplished to share the TLS Session and enabled the fork to understand the received initial packet, in which way whatsoever, there is waiting another task for us!
HTTP/2
HTTP/2 is awesome, as SPDY is. One can see HTTP/2 as the successor to SPDY, as already mentioned, google has dropped SPDY in favour of HTTP/2, but also HTTP/2 was also the basis of the work on HTTP/2 which is still work in progress. It makes the Web faster not only by utilizing streams and muxed streams like SPDY does, but also reducing the amount of data transferred in every packet by compressing the headers, which SPDY did via the DEFLATE compression algorithm, HTTP/2 comes with HPACK. Naturally this doesn't really speeds up anything, in term of computing, but we need to transfer less data and at last the internet connection is still the slowest component. Especially low bandwith devices suffer from huge headers, increasing the time until they downloaded the complete request and thus actually see the website they were visiting. So HTTP/2 does again one thing, that forces us to spend some cycles to decompress this header informations, before we finally can parse them.
While HTTP/2 also offers via Literal Header Field never Indexed, which would enable to avoid compression of specific header fields and thus we may be able skip decompressing the information, we assume for now we need to decompress it.
So finally we're able to read the information we want, may it be the IP Address or any other information we get from the header. And again, our forks will also decompress the header informations a second time, like they do for SSL. Everything explained for SSL applies here, too.
So far so good, but this all wasn't the reason why I started this blog post. The questions inspired me to think about how I treat network connections and when I treat them as being safe. Taking us to the next topic.
When does traffic needs to be encrypted
The following needs us to answer some questions:
- Do wo transmit our data over an insecure channel?
- Do we even transmit our data over the network, or do we talk over unix domain sockets?
- Are we already communicating over an encrypted VPN?
So to be able to decide if we need to encrypt our data, after it has entered our DC or Infrastructure within a DC, we should have at first a secure setup, thus we need to make sure we are segmenting and isolating our network. First of all never use Hubs, but I don't assume that anyone outside of his home would ever get the idea to use a hub instead of a switch. A switch makes it at least harder to sniff within the Network, you should also watch out to install ARP Spoofing detections. But I'm drifting out into details...
To make it short, we need to look is our channel already secure, because there is an encrypted VPN. Or is even the wire secure and we don't need to encrypt in this segment again?
In fact, it's hard to get the right decision. Either we transfer not encrypted in a secure area, in favour of the performance.
Or...

Fact is, we can't guarantee that current encryption algorithms never going to break. But to encrypt everything is surely, the most secure approach to ensure the security of our data. But encrypting data is costly and that means it does make sense to think about it once again if it is really valueable to encrypt data within an already theoretically secure network. Because if someone breaks in and steals data, he probably targets the databases before his intrustion gets detected and doesn't try to sniff within a switched network in which he must use ARP Spoofing, which is clearly not what he wants if he don't want attention from the SysAdmins.
The only interesting thing for attackers which they could sniff on the Network anyway may be only passwords, which can be protected in other ways, may be I going to make a blog post over this too, or highly sensible data like payment details. But again, the databases are most probably going to be the first target.
Layer 4 - Data that helps balancing even more
Beside from all the Stuff and explanations before, let us finally talk about why using informations from OSI Layer 4 can help balancing even more effective.
To note: I omit all layers above Layer 4 for now, most of the information we read belongs to Layer 7, but I do care only about having the raw tcp connection available and don't about the protocols like http.
So let's assume we have Network architecture where the traffic from the internet first passes our Hardware Load Balancer after entering the DC. The load balancer now balances traffic between our frontends. Let's say we have two of them, our Hardware Balancer works on Layer 2, thus preserves the real IP. It could hash balances via the source IP, so we would need to adjust our balancing on the front end nodes and make them aware of this. But for this time we let him balance just all request evenly, doesn't make him care of sticky-sessions. We would reach a similar behavior if we have different A/AAAA-Record entries linked to our domain, but it wouldn't be really even anymore.
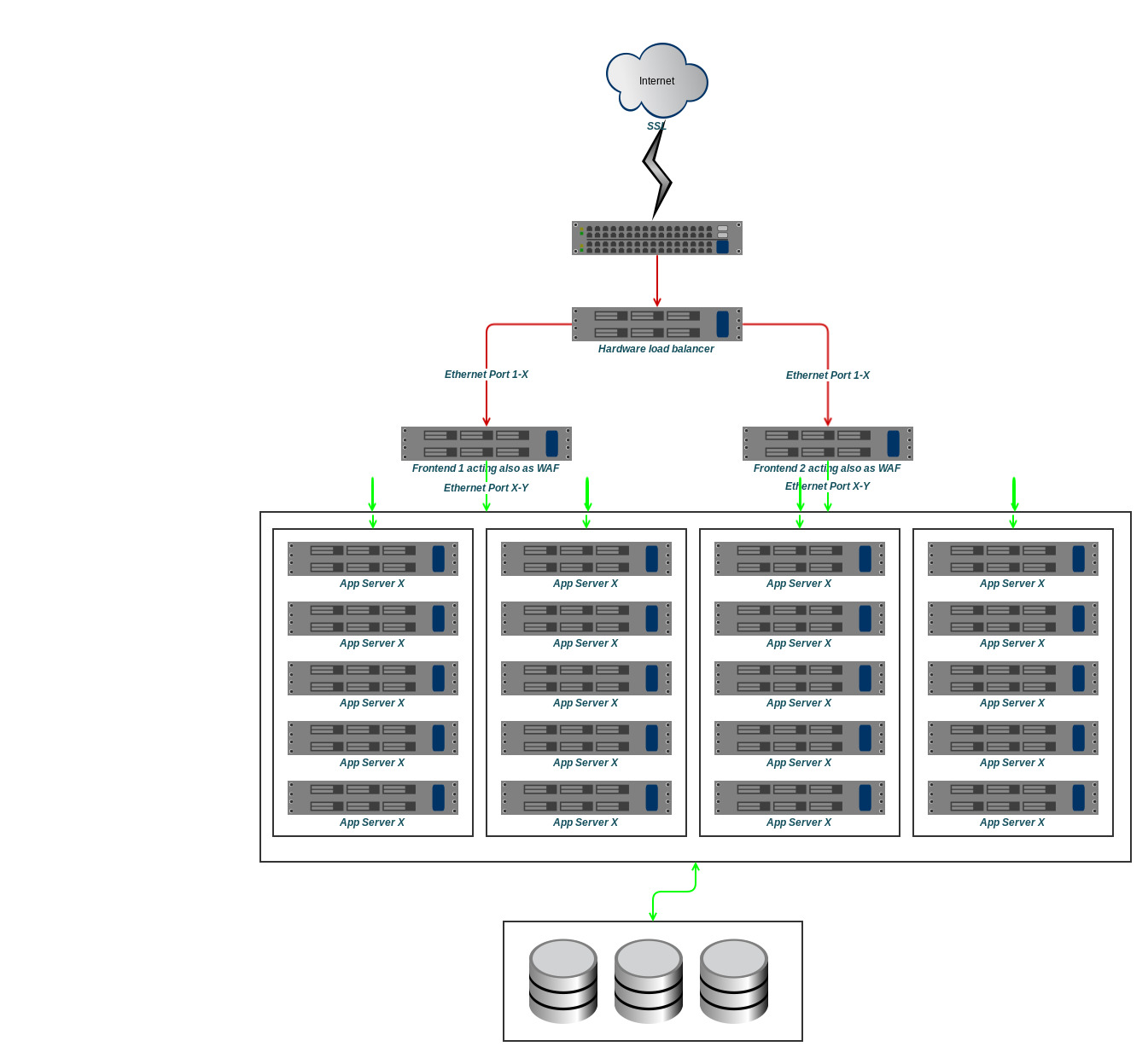
So imagine this crude Diagram represents our Network. The green arrows mark the safe pathes, where we could send data in plain. The frontends are connected with 4 different wires to the 4 segments of app servers which are again switched. So both servers have access to all app servers, and we're going to serve static content directly from the frontend, at least the assets we don't serve already from a CDN, for example user avatars and stuff, that might be picked up by the CDN later. Our dynamic content gets delivered by our app servers, which our frontend servers do the load balancing for.
So we're running NGINX on our frontends, but how do we balance this traffic? If you access the other frontend our balancing might balance in a similar way. If completely configured identically, the hash calculation should also behave identically. But lets assume, we want to add dynamically new Servers to the Structure. This would generate problems, as the hash balancing wouldn't fit here anymore.
Balancing via Session cookies, what we can do now is to start balancing our application and letting NGINX set a cookie for the user, which it can use the next time to identify, which backend node is the one the user desires. This needs of course a bit more to setup, we do not want that an attacker might abuse this cookies, thus the user should not be able to easily modify the cookie to transfer him to one special server. Possibly the easiest solution is to use encryption on those cookies.
Another solution would be a shared storage, probably a memory storage, something like memcached where information about balancing targets could be stored.
Finally now we would have a working balancing and the capability scale on demand, ever if the application is explicitly build to save its sessions to shared storages. We also transfer everything after the frontends in plain text and decrypt and encrypt the traffic from and towards the internet at them. Thus we have a fast communication between backend Servers and frontends and in the end a faster response time when communicating with our user.
Conclusion
We ensure the security of our Network by highly segmenting parts of it and strictly control which servers can communicate with which other servers. Doing this by going over entirely different wires, using a switched Network and use solutions to detect attacks. Like IDS and ARP Cache poisoning and Spoofing detections.
Now we're going to decrypt our traffic as soon as it reaches the first Frontend and keep communicating plain with the app servers. HTTP/2 still provides the possibility to use it without SSL, the "SSL only" does only apply to "browsing the open web". Or to quote:
Mark Nottingham - To be clear - we will still define how to use HTTP/2.0 with http:// URIs, because in some use cases, an implementer may make an informed choice to use the protocol without encryption. However, for the common case -- browsing the open Web -- you'll need to use https:// URIs and if you want to use the newest version of HTTP.
And we may also utilize Literal Header Field never Indexed to avoid compression of our needed information, thus we keep the overhead as small as possible when the traffic is already in our network.